在 .NET 生态中,如果你正在寻找一个轻量级、高性能且跨平台的 PDF 处理库,Docnet 是一个值得推荐的选择。它封装了 Google Chromium 使用的 PDF 渲染引擎 PDFium,提供了强大的 PDF 文档读取、解析、渲染等功能,并且完全支持 .NET Standard 2.0,适用于 Windows、Linux 和 macOS。下面我们来介绍下这个库。
应用场景
• 将 PDF 页面转为图像,用于预览功能
• PDF 文本提取与 OCR 结合,构建文档检索系统
• 解析 PDF 表单或合同内容,用于自动化归档
• 将扫描图片(JPEG)转换为 PDF 进行存档
核心功能一览
页面与文档信息
• 获取 PDF 版本
• 获取页面数量
• 获取页面宽高
• 获取页面旋转角度
文本与结构提取
• 提取完整文本内容
• 获取字符集合及其边界框(bounding box)
• 获取字符字体大小、角度
图像渲染
• 将 PDF 页面渲染为 PNG 图像
• 支持字符边框叠加显示(用于调试或文本定位)
文档操作
• 拆分 PDF 文档
• 合并多个 PDF 文件
• 解锁受密码保护的 PDF 文件
• 将 JPEG 图像转换为 PDF 页面
入门指南
通过 NuGet 安装
dotnet add package Docnet.Core
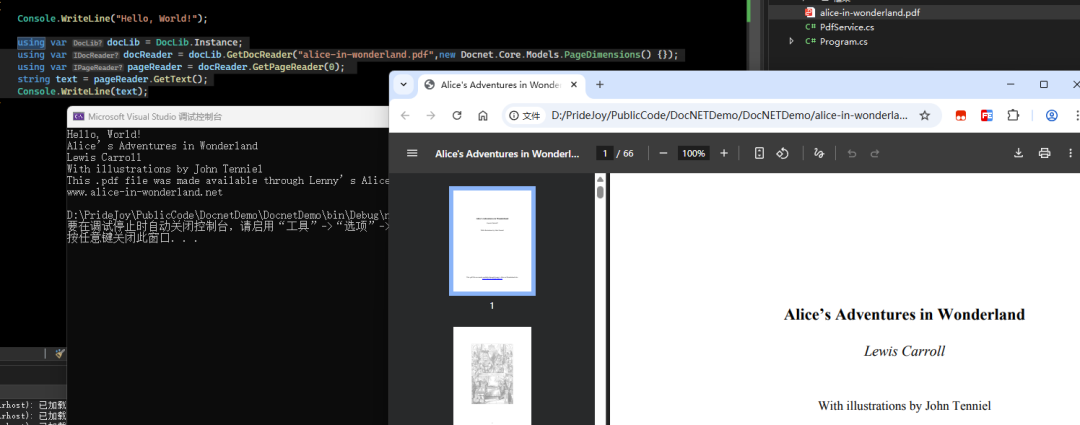
1. 提取页面文本
using Docnet.Core; usingvar docLib = DocLib.Instance; usingvar docReader = docLib.GetDocReader("alice-in-wonderland.pdf", new Docnet.Core.Models.PageDimensions() { }); usingvar pageReader = docReader.GetPageReader(0); string text = pageReader.GetText(); Console.WriteLine(text);
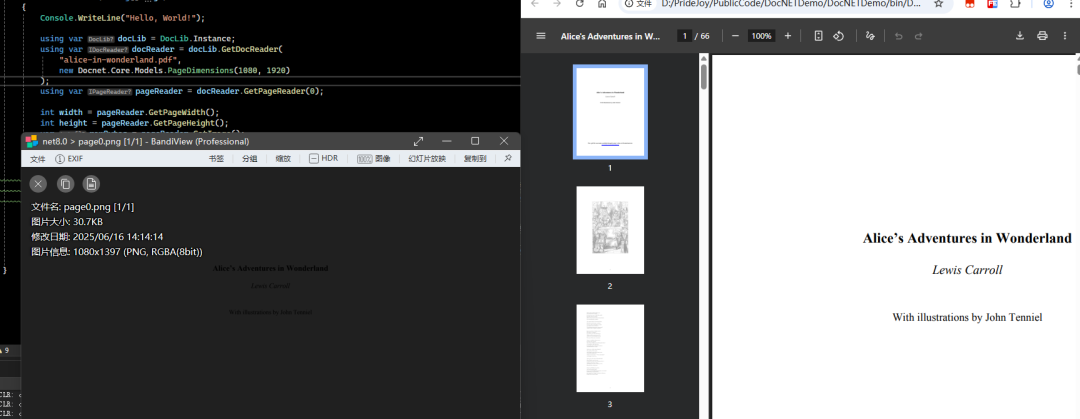
2. 渲染 PDF 页面为图像
using Docnet.Core; usingvar docLib = DocLib.Instance; usingvar docReader = docLib.GetDocReader( "alice-in-wonderland.pdf", new Docnet.Core.Models.PageDimensions(1080, 1920) ); usingvar pageReader = docReader.GetPageReader(0); int width = pageReader.GetPageWidth(); int height = pageReader.GetPageHeight(); var rawBytes = pageReader.GetImage();






 400 186 1886
400 186 1886


