


[点晴永久免费OA]PDF 里的表格复制到崩溃?这个免费开源工具能直接导出 Excel
别人发来一份 PDF 报价单,让你把里面的表格整理进 Excel。
看着不难,真动手就很烦:框选后不是错位,就是整列挤成一行,最后还得自己慢慢抄。
如果你也经常碰到这种“表格明明在 PDF 里,却没法直接拿来用”的情况,可以试试 Tabula。
它是一个老牌开源工具,专门干一件事:把 PDF 里的表格提取出来,导出成 CSV / Excel 能继续处理的格式。
对这类需求来说,Tabula 的价值很直接:省掉手抄表格这一步。
我专门拿了一页样例 PDF 跑了一遍,左边是原表格,右边是实际提取出来的结果表。
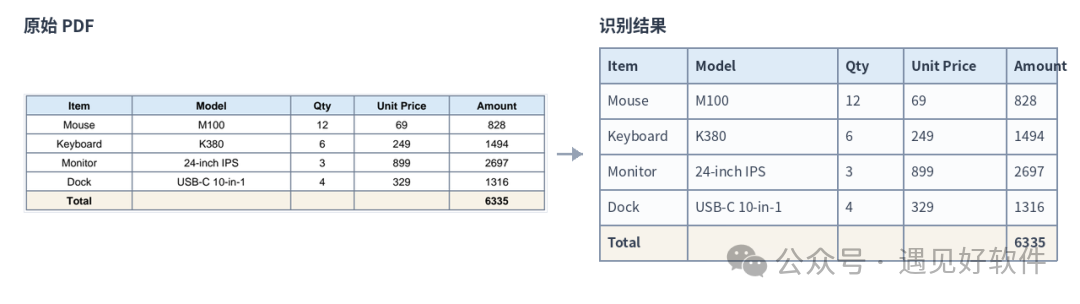
如果 PDF 本身排版规整、文字可以正常选中,Tabula 提出来的效果通常就像这样:结构完整,后面进 Excel 再筛选、汇总、改格式都比较顺手。
很简单,就 4 步:
它的思路不是花哨的“全自动 AI”,而是让你先告诉它:这块区域是表格。
所以在很多排版规整的 PDF 上,它反而挺稳。预览时如果发现列没有对齐,可以回到上一步重新框选,或者尝试切换不同的提取方式。它不像现在一些 AI 工具那样“自动猜完一切”,但也正因为这样,你更容易知道问题出在哪。
不会用到一半弹出“开会员才能导出”。
官方写得很明确,只要浏览器地址栏还是 localhost 或 127.0.0.1,PDF 和提取出来的数据都在本地机器上处理,不会经过外部服务器。处理报表、合同附件这类内容,会更安心。
如果 PDF 里的文字本来就是可选中的,Tabula 往往能比较顺利地把表格拉出来。
Windows、macOS、Linux 都能用。Windows 和 Linux 需要装 Java,Mac 版自带 Java,装完打开浏览器就能开始提取。

它不适合扫描件。
官方 README 和官网都写得很明白:Tabula 只适合 text-based PDF,不适合扫描版 PDF。也就是说,如果你的文件其实是一张图片塞进 PDF 里,那它大概率帮不上忙。那种情况应该去找 OCR 路线工具,而不是硬拿 Tabula 顶。
另外,它也不是那种还在高速迭代的新项目。官网显示当前稳定版还是 1.2.1,发布时间已经比较早;GitHub 上维护者也明确说过,主应用短期内不太会有大更新,更多是底层的 tabula-java 偶尔继续修 bug。
但这不一定是坏事。
因为 Tabula 的定位一直很清楚:
不是炫技,而是老老实实把 PDF 表格弄出来。
如果你要的是“把这份 PDF 里的表格先抠出来,后面我自己进 Excel 再整理”,它依然是个非常顺手的工具。
✅ 经常处理 PDF 表格的人
✅ 想继续在 Excel 里筛选、统计、汇总的人
✅ 在意隐私、不想上传文件的人
✅ 做财务、采购、行政、研究、数据整理的人
⚠️ 如果你处理的主要是截图、照片、扫描版 PDF,那应该去找 OCR 工具,不该选 Tabula。
如果你只是想直接下载来用,不想研究 GitHub 页面,可以直接点官方发布地址:
官方安装方式也很朴素:
tabula-win-1.2.1.zip,解压后运行 tabula.exetabula-mac-1.2.1.zip,解压后打开应用tabula-jar.zip,装好 Java 后运行 tabula.jar正常情况下,它会自动在浏览器里打开 http://127.0.0.1:8080/。
如果打不开,通常就两个原因:
如果你平时懒得记这些地址,最省事的方法就是先把官网存一下:
如果你也被 PDF 里的表格折磨过,这个工具值得存一下。下次再收到那种“看得见但用不了”的 PDF,至少不用第一反应就是手抄了。
你平时最烦哪类 PDF:报价单、财务报表,还是论文里的表格?
