


为什么阿里等大厂禁止使用三表以上的JOIN?3种替代方案
你开发时有没有过把三四张表一股脑 JOIN 在一起的经历,反正我是有过的,本地开发测试时跑得飞快,一上线就慢查询告警刷屏,甚至可能直接把业务干崩了。一查发现是自己写的多表JOIN惹的祸,觉得冤不冤?
我们原来公司要求每个人都要学习阿里的java开发规范,还要求每人都要考过阿里的考试,我记得当时还要19.9一次。阿里的 Java 开发规范有一条 "禁止超过三张表进行 JOIN 操作" 。估计不少人都当 "教条" 看过,但其实这条规范背后,是阿里在亿级流量下踩过无数坑才总结出的经验。今天咱们就从 MySQL 执行引擎的底层逻辑聊起,把这条规范的底裤都扒出来,顺便看看遇到多表关联场景该咋解决。
先看个电商场景的血泪案例:某平台的早年的一个程序员写的订单查询接口,为了一次性返回订单、用户、商品、仓库的全部信息,写了这么一段 SQL:
SELECT o.*, u.name, u.phone, p.product_name, w.warehouse_name
FROM orders o
JOIN users u ON o.user_id = u.user_id
JOIN products p ON o.product_id = p.product_id
JOIN warehouses w ON o.warehouse_id = w.id
WHERE o.status = 1;看起来好像没啥问题是吧?但上线后直接炸了:
为啥会这样?咱们得从 MySQL 的 JOIN 底层逻辑说起。
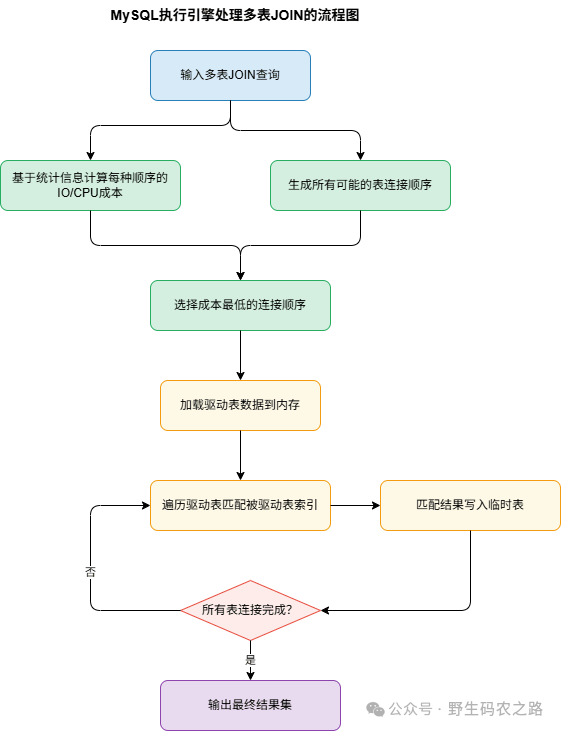
你可能不知道,MySQL 在 8.0.18 版本之前,只支持嵌套循环类 JOIN 算法,没有 Hash Join 和 Sort-Merge Join 这些更高效的算法。这三种嵌套循环算法的问题在哪呢?



从 MySQL 的源码来看,优化器在处理多表 JOIN 时,需要先确定表的连接顺序,而可能的连接顺序是阶乘级增长的:
MySQL 的优化器并没有足够的时间去穷举所有可能,它用的是贪心算法—— 每次选择当前看起来最优的连接顺序,而不是全局最优。当表的数量超过 3 张后,这种局部最优的选择很容易掉进坑里,就像刚才那个案例一样,选错了驱动表直接导致全表扫描。
而且优化器的决策严重依赖表的统计信息,如果统计信息过时或者不准,那结果就更不可控了。我经常会碰到,表数据变动了(增删了),但统计信息没更新,优化器还是按原来的数据量选驱动表,结果查询直接崩了。
多表 JOIN 还有个更隐蔽的问题:中间结果集的内存消耗。
每一次 JOIN 都会生成一个中间结果集,MySQL 会先尝试把这个结果集放在内存里的 JOIN Buffer 里,但如果结果集太大,就会生成临时表写到磁盘上。你想想,3 张表 JOIN 的中间结果集可能就有几十万行,再 JOIN 第四张表,数据量直接指数级膨胀,临时表能占几个 G 的磁盘空间,IO 直接拉满,整个数据库都会变慢。
像阿里这类业务基本都是分库分表的分布式架构,这时候多表 JOIN 的问题就更严重了:
在分布式数据库里,要避免网络间大量数据传输,而JOIN 需要跨节点、跨分片传输数据。比如订单表在 A 节点,用户表在 B 节点,仓库表在 C 节点,那多表 JOIN 时,数据要在 A、B、C 之间来回传输,网络直接成了瓶颈。
我们曾经内部的实测数据显示,单分片查询只需要 25ms,跨分片四表 JOIN 直接涨到 1200ms(好在不是线上,否则直接要成盒了),网络流量更是从 5KB 涨到了 120MB,差了 24000 倍!
分库分表中间件比如 DRDS,很难把复杂的多表 JOIN 下推到存储节点,只能在中间层拉取所有数据再做 JOIN,这不仅慢,而且很容易因为数据量太大直接 OOM。
还有更要命的问题--分布式事务问题。多表 JOIN 如果涉及到跨库修改,那分布式事务的一致性问题会让你头大,性能也会掉一半以上。
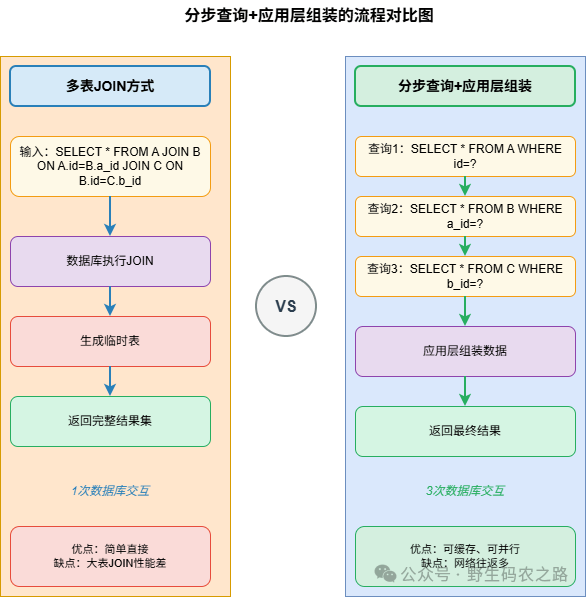
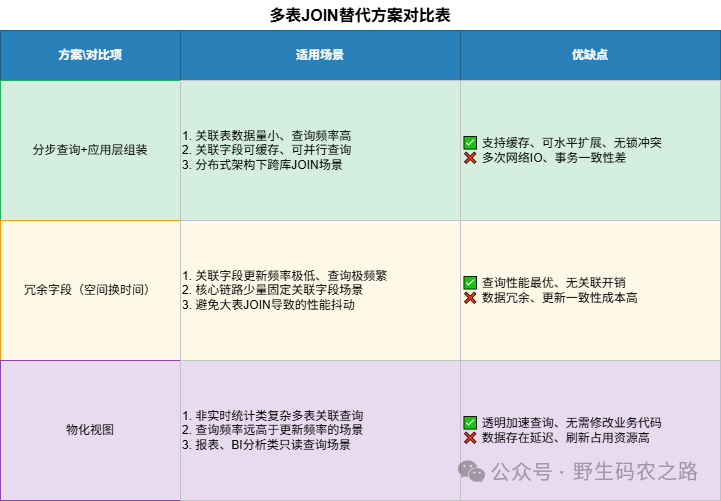
既然多表 JOIN 这么坑,那遇到需要多表关联的场景该咋办?通常有三个实用的解决方案。
思路简单直接粗暴,既然JOIN走不通,那就把复杂的多表 JOIN 拆成多次单表查询,然后在应用层把数据组装起来。比如刚才那个订单查询的场景,可以这么改:
// 1. 先查订单主表数据
List<Order> orders = orderDao.query("SELECT * FROM orders WHERE status=1 LIMIT 100");
// 2. 提取关联的用户ID、商品ID,去重
Set<Long> userIds = orders.stream().map(Order::getUserId).collect(Collectors.toSet());
Set<Long> productIds = orders.stream().map(Order::getProductId).collect(Collectors.toSet());
// 3. 批量查询用户和商品数据
Map<Long, User> userMap = userDao.queryByIds(userIds).stream()
.collect(Collectors.toMap(User::getId, Function.identity()));
Map<Long, Product> productMap = productDao.queryByIds(productIds).stream()
.collect(Collectors.toMap(Product::getId, Function.identity()));
// 4. 应用层组装数据
orders.forEach(order -> {
order.setUserName(userMap.get(order.getUserId()).getName());
order.setProductName(productMap.get(order.getProductId()).getName());
});这种做法有什么好处呢?
如果是高频查询的场景,比如订单列表要显示商品名称、用户昵称这种不常变的字段,那可以直接把这些字段冗余到订单表里,彻底避免 JOIN。这也是我们很常用的一种方式,但是要适度,相对来说更克制一些,因为如果处理不好很容易带来数据不一致的。
比如修改订单表结构:
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
user_id BIGINT,
product_id BIGINT,
product_name VARCHAR(100), -- 冗余商品名称
user_name VARCHAR(100), -- 冗余用户昵称
order_time DATETIME,
status TINYINT,
INDEX idx_user_id (user_id)
);但冗余字段要注意三个原则:
这种通常是报表场景。如果是实时性要求不高的报表、分析场景,那可以用物化视图或者汇总表,提前把多表关联的结果计算好,查询的时候直接查预计算的表就行。这种其实还是很常见的,只要实时性要求没那么高,很多都是通过大数据跑批的方式形成大宽表供业务使用。
比如创建一个订单详情的物化视图:
CREATE MATERIALIZED VIEW order_detail_view
AS
SELECT o.id, o.order_time, u.name, p.product_name, o.amount
FROM orders o
JOIN users u ON o.user_id = u.user_id
JOIN products p ON o.product_id = p.product_id
WHERE o.status = 1
WITH DATA;然后定时刷新这个物化视图,比如每小时刷新一次,查询的时候直接查这个视图就行,响应时间能从几百 ms 降到几 ms。
这三个方案也不是互斥的,是对应不同场景的替代。可以都用,也可以选择性的用。
当然,这条规范也不是绝对的,毕竟规矩是死的,人是活的,只要知道原理,还是可以适当利用的。其实这三种场景可以适当放宽的:
不过规范也不是什么金科玉律。其实禁止三表以上 JOIN,本质上是架构思维的转变:
其实哪怕是允许的双表 JOIN,也要记住三个原则:
大厂的规范从来不是拍脑袋想出来的,都是无数坑踩过后才总结出来的经验。以后看到这种规范时,多问几个为什么,多想想背后的原因,自然就有答案了,知其然知其所以然。
阅读原文:https://mp.weixin.qq.com/s/S6Mo-H3MoSgiaAUzlOtQNg
